Real-time dreaming 邊想邊做
這個模式就像是:“我一邊想,AI 一邊跟著我動。”不是你寫一堆 prompt 然後點選 “生成”,
也不是你改了東西等半天出結果,而是:你拖一下,AI 馬上給反饋;你換個詞,馬上出畫面。
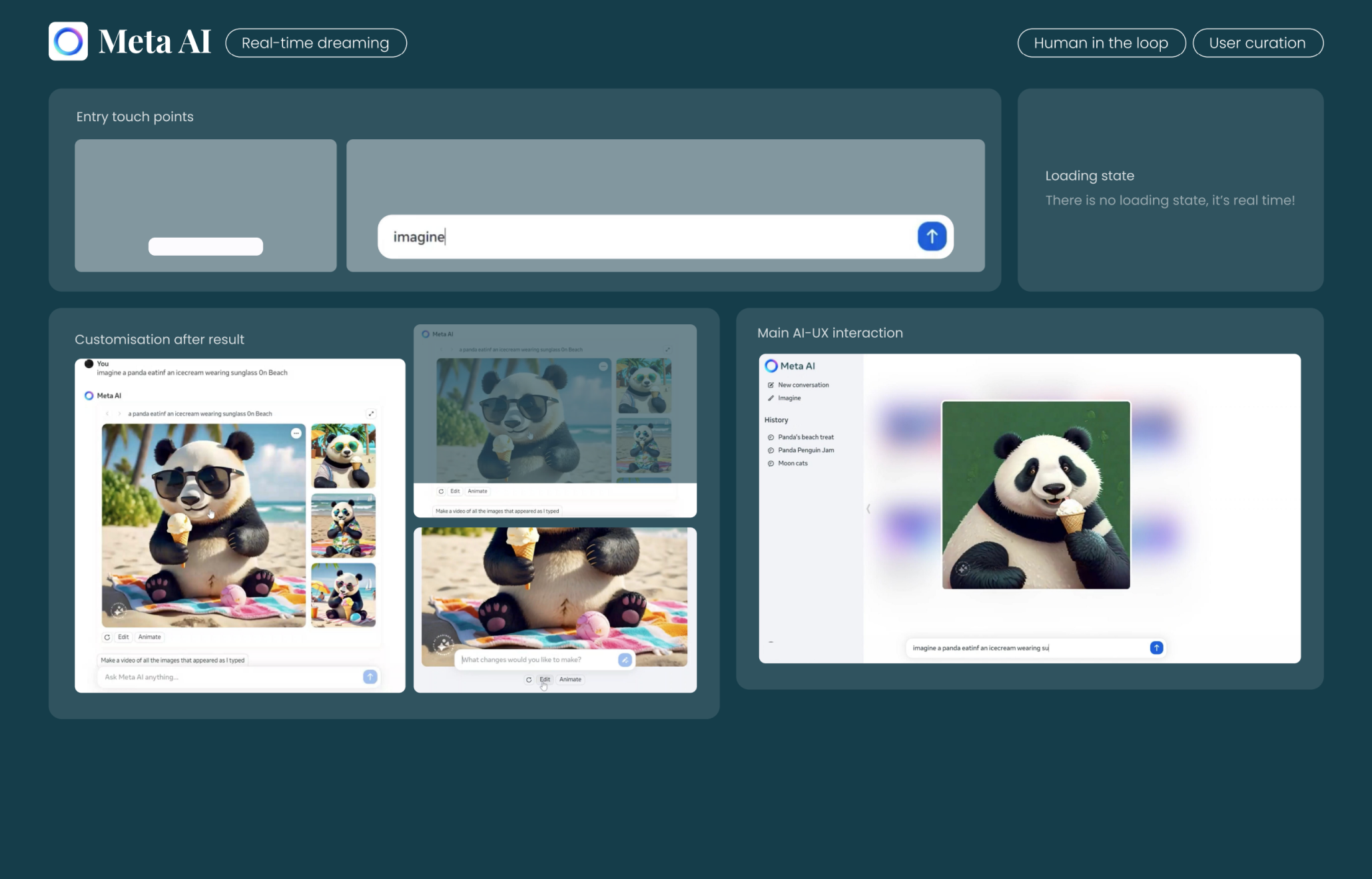
Meta AI 透過極致實時的生成反饋,讓使用者獲得近乎“夢境式”的內容體驗:邊打字邊看圖變,一秒進入創作狀態,無需任何點選與等待。
入口觸點(Entry Touch Points)
- 使用者透過輸入框直接發起想象式 prompt,例如:
imagine a panda eating an ice cream wearing sunglasses on beach
- 不需要點選複雜操作,一句話觸發整個流程
Main AI-UX interaction(主互動介面)
- 介面左側保持對話上下文(conversation thread),右側即時渲染生成的影象
- 使用者只需調整 prompt 文案,AI 會立即響應新輸入,影象動態變化
- 全程無停頓切換,無中斷,維持沉浸式體驗
Loading state(載入狀態)
- 明確強調:「沒有載入狀態,這是實時的!」
- 影象生成過程中,系統透過模糊過渡或 placeholder 圖片平滑顯示生成結果,完全隱藏系統處理細節
Customisation after result(生成後的定製操作)
- 生成影象後,使用者可直接點選圖片進行動畫處理或更改 prompt 再生圖
- 系統支援:
- Edit 按鈕 → 進入更精準微調模式
- Animate 按鈕 → 將靜圖轉換為影片
- 可複用、重塑、迴圈生成,保持使用者在創作流程內
Example output(示例結果)
- 高保真影象直接嵌入主對話中,使用者可以複製、儲存、繼續對話、生成動畫
- 影象生成帶有隨機性,每次細調 prompt 都可探索不同創意空間
專業邏輯亮點總結:
- 文字驅動 → 實時視覺生成:不再是“寫完 prompt 點一下生成”,而是邊打字邊看圖自動長出來
- 無縫反饋,連貫操作:隱藏掉所有傳統生成 AI 的等待與確認動作
- 保持主線創作流:每一次微調都不會中斷使用者注意力,生成結果即反饋結果
- 支援二次創作迴圈:Edit/Animate 功能,延展出更多創作可能,而不是“一次性生成”
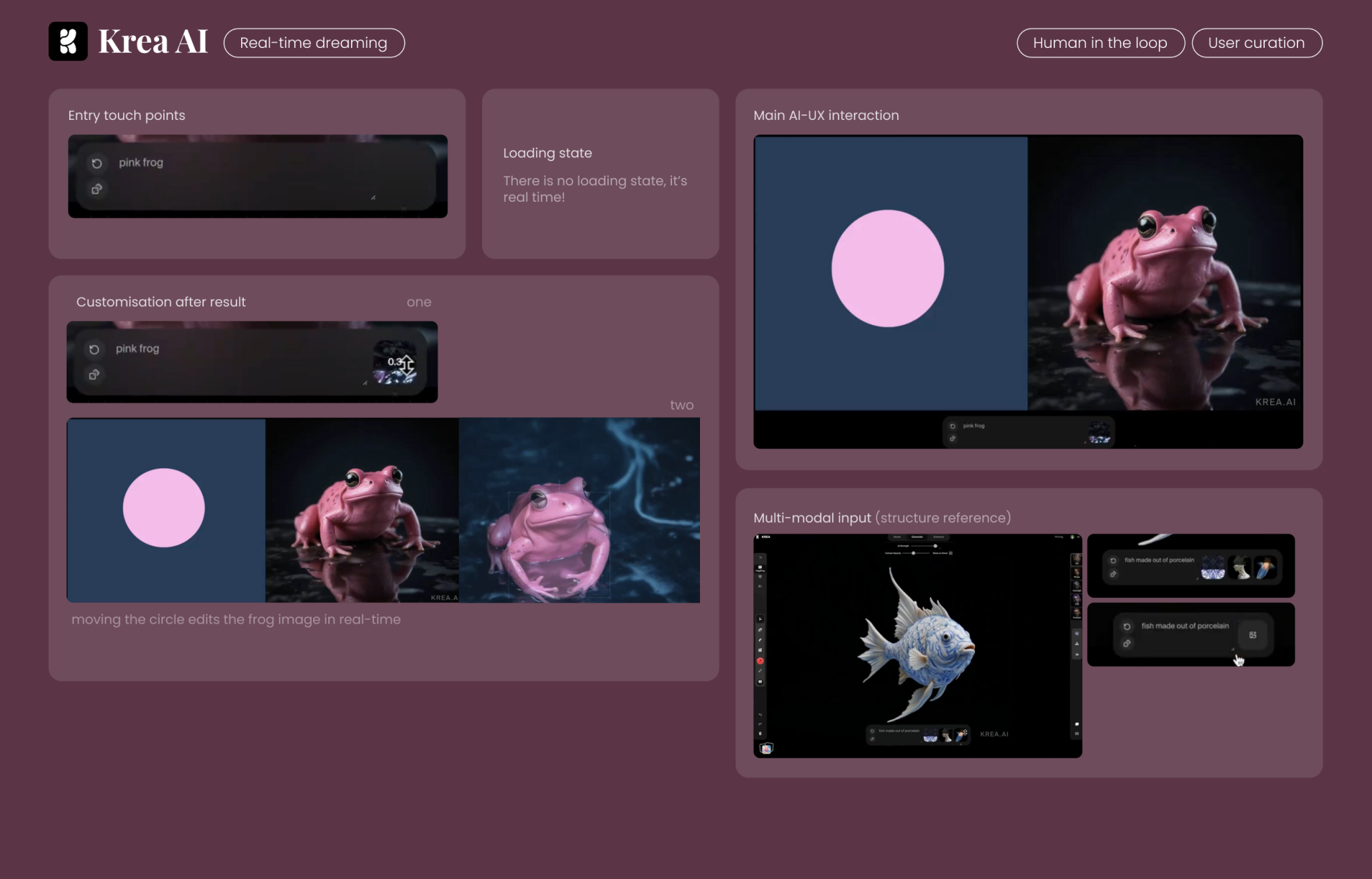
Krea AI 是真正意義上「所見即所得」的視覺創作工具。在它的系統中,AI 已不再是一個“生成”工具,而是一個實時反應的共創搭檔——你動一下,圖就變一下,靈感完全不需要等。
入口觸點(Entry Touch Points)
- 使用者透過輸入一個非常簡單的 prompt,如:
pink frog(粉紅青蛙)
- 無需點選按鈕、提交、等待,只需輸入文字就立即觸發生成
- 入口體驗極簡,prompt 框與畫面幾乎無縫整合在介面中
Main AI-UX interaction(主互動介面)
- 顯示左側為幾何圖形(如粉色圓形),右側為生成影象
- 畫面分割槽明確,生成內容實時更新,隨著輸入、圖形移動、prompt 調整同步變化
- 整個過程無“生成按鈕”,動作即請求、拖動即變化
Loading state(載入狀態)
- 明確提示:“沒有載入狀態,這是實時的!”
- AI 輸出過程隱藏在互動動作之後,不中斷、不干擾
- 使用者看到的只有視覺結果的變化,而不是“AI 正在思考”
Customisation after result(生成結果的定製)
- 結果不是“完成圖”,而是可實時調節的動態畫布
- 使用者可以拖動左側的粉色圓形,實時改變影象中青蛙的形態、風格、細節
- 也可以直接修改 prompt,立即出現新版本
- 更像是一個視覺調色盤,而不是傳統“生成→看結果”的工具
Multi-modal input(多模態輸入)
- 支援結構提示 + 文字 prompt 的組合輸入,例如:
- 結構:上傳魚的輪廓圖
- prompt:
fish made out of porcelain(瓷器做的魚)
- AI 實時根據結構參考 + 描述生成高一致性的影象結果
- 極大程度釋放使用者的表達自由度和掌控力
Example output(示例結果)
- 輸出影象質量高、細節豐富
- 無需反覆迭代確認 prompt,也不需要手動點“生成”
- 使用者每次的視覺動作和語言指令都會同步轉化為影象反饋
- 整體是一個持續演化的畫面,而非靜態的最終圖
專業亮點邏輯總結:
- 視覺調參新正規化:Krea 並非“提示詞生成圖”,而是“影象 = prompt + 動態操作”的實時共創模型
- 空間+語言混合驅動:支援結構草圖 + 文字描述共同驅動影象變形,這是一個典型的多模態互動設計突破口
- 打破等待 → 實時響應:不僅沒有 loading bar,連“結果”這個概念都被重構為一個可操控的狀態流
- 使用者感知是“控制”,而不是“請求”:讓使用者感到“我在創作”,而非“我在等 AI 給我一個答案”

Decohere 不是讓你一鍵生成影象,而是讓你可以逐步完善、實時預覽、連續微調。它構建了一種“可對話”的 AI 影象創作體驗 —— 就像你和 AI 一起搭積木,一塊一塊加上去,圖就越來越像你想要的樣子。
入口觸點(Entry Touch Points)
- 使用者在輸入框中輸入完整 prompt,如:
a cat reading a book in a library setting cozy environment
- 系統自動開始生成,無需點選“生成”按鈕
- 支援追加或編輯 prompt,實現連續性構圖
Loading state(載入狀態)
- 有輕微的 loading 動畫(頂部有進度條提示),但極短暫
- 頁面保留 prompt 編輯框,使用者知道 AI 正在響應指令
- 明確強調:“Slight loading, good user feedback!”(輕量載入,使用者反饋好)
Main AI-UX interaction(主互動介面)
- 生成區域為主圖展示區,prompt 編輯區疊加在圖下
- 使用者可以在已有圖片基礎上,繼續追加描述
例如:
generate an image of cat where they are reading books around library and it was surrounded by mountain region and wear cat a glass and a cap
- 整個體驗是**“持續構圖 + 區域性增強”**,不是一次性生成即完結
Customisation(生成後的調整)
- 使用者可以左右滑動不同變體,選擇更喜歡的版本
- 選定版本後,可直接在其基礎上輸入新的 prompt 進行微調
- 整體體驗就像:
“先畫輪廓 → 選擇構圖風格 → 再塗細節 → 再加配飾”
- 真正做到“逐幀生長”,使用者可對每一個階段保持控制權
Multi-modal input(多模態輸入)
- 支援結構參考圖 + 文字 prompt 的結合使用:
例如上傳人物照片 → prompt:
aztec warrior
- 最終生成影象會保留人物五官結構,但風格、服裝、背景全部替換為 prompt 所描述的內容
- 是一種非常適合“替身生成”、“IP視覺再創作”的多模態方式
Example output(示例輸出)
- 場景:山間圖書館,貓咪戴著眼鏡看書
- 輸出影象自然度高、敘事性強,且使用者能夠層層細化
- 每次微調都不會完全“洗掉”原始構圖,AI 會努力理解你的上下文
專業亮點邏輯總結:
- 支援連續疊加的 Prompt Engine:不像傳統 AI 工具一次出圖,Decohere 支援 prompt 追加和演化(iterative generation)
- 選擇變體 → 基於選中圖繼續拓展:建立類似“版本樹”的編輯體驗,每張圖都可以當作下一步的起點
- 極強的使用者控制感:不只控制初始構圖,還能區域性增強、風格演變、背景再設定
- 載入反饋輕柔克制:避免打斷感,真正做到“生成不打擾,反饋不消失”